What Is Index-Based Backup?

In a world where data has become the backbone of businesses, backup methods have had to evolve to keep up. One of the most recent developments, especially with the rise of object storage, is the "index-based" backup method.
Unlike traditional methods that relied on a hierarchical file structure, index-based backups offer a more flexible and optimized way of managing data through specific indexes that track and record each change efficiently. But what does this really mean? Let’s dive into the details to better understand this approach.
Definition
Before anything else, let’s start by defining the term "index-based backup." What better way to do this than to ask ChatGPT to help us with the task?
Index-based data backup is a backup approach that uses indexes to track and record the files or data blocks to be backed up. This method relies on the creation and use of an index that contains key information about the files, such as their location, size, timestamp, and other metadata. The index simplifies and optimizes backup operations.
Traditional backup methods
Now, I’d like to give you a quick reminder of the "traditional" backup methods. These are the ones you’ll often find in most articles discussing data backup techniques.
There are three main types, which will help you understand the historical paradigm:
- Full Backup: Each backup captures all data. While this ensures an exact copy of the files, it can quickly become costly in terms of space and time.
- Incremental Backup: Only the changes made since the last backup are captured, reducing the time and space required, but making restoration potentially slower since each change must be reapplied in succession.
- Differential Backup: Similar to incremental, but it captures all changes since the last full backup. Restoration is faster than with incremental, but it requires more storage space.
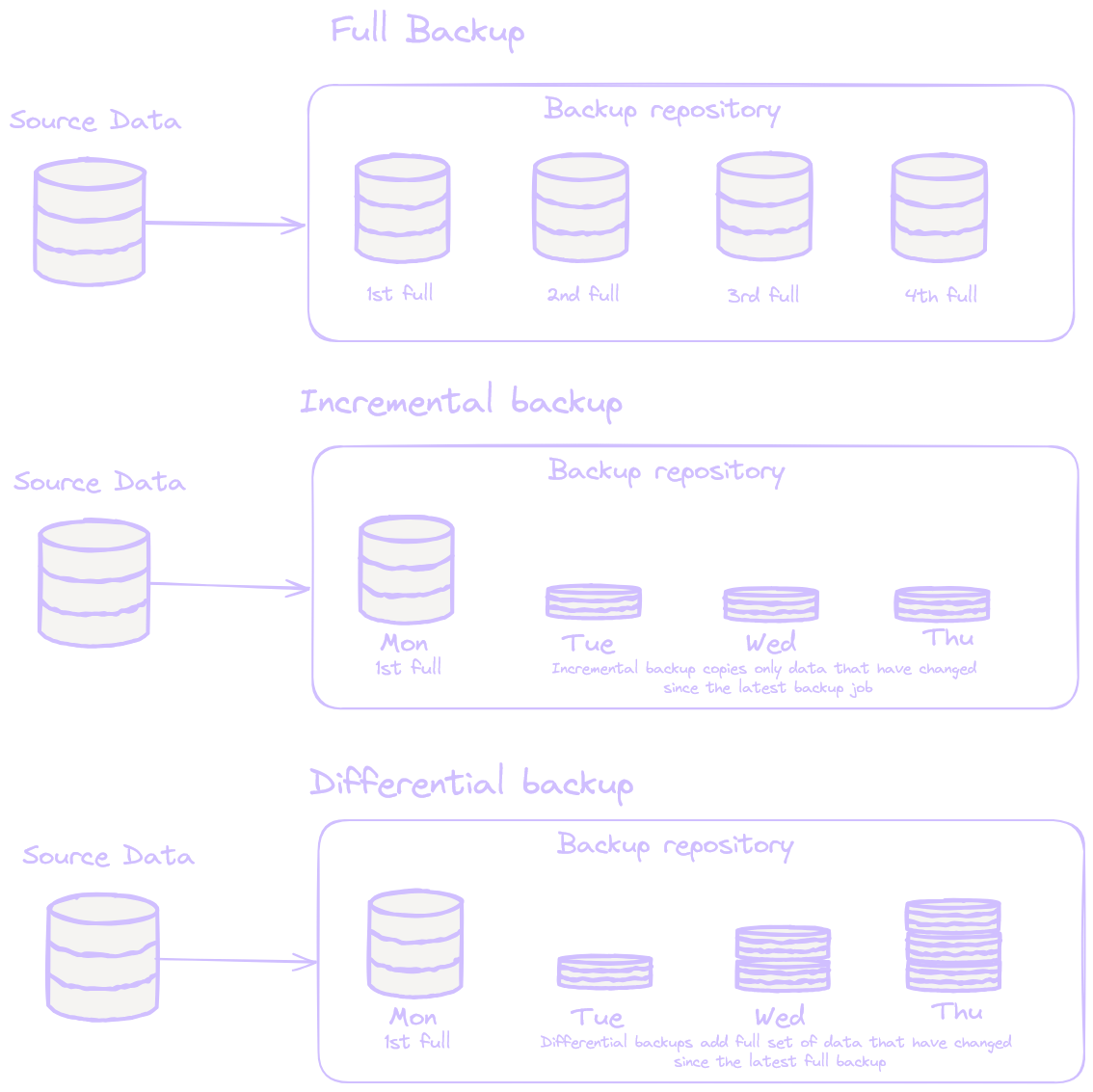
These traditional methods have been widely used in environments based on hierarchical file systems. However, the rise of object storage has fundamentally shifted this dynamic and changed the game for data backup.
The rise of object storage
With the increasing adoption of object storage, the limitations of traditional methods have become more apparent. Object storage, often used in cloud environments, employs a flat architecture.
Unlike a file system that organizes data into folders and subfolders, object storage lacks a natural hierarchy; it stores files as objects within a "bucket." Each object is identified solely by a path that acts as a prefix, without a true sense of file hierarchy.
For example, a file named /tmp/mytestfile is simply an object with that name in the bucket, at the same level as all other objects.
This shift in paradigm has accelerated the emergence of index-based data backup:
- Why maintain a hierarchical backup structure when object storage eliminates it?
- Why keep dependencies on previous incremental backups, which complicates the restoration process?
Instead of viewing file backup as a set of directories, we’ve abstracted the notion of hierarchy. A backup is now just a list of files (an index) linked to a data repository (bucket) containing the useful data. All we need to do is scan an index and download the referenced files to restore a backup. Pretty cool, right? 😁
So, how does "index-based" backup work?
In practice, index-based backup follows a three-step process:
- Metadata indexing: The backup tool scans the metadata of the files or data blocks to be backed up (name, size, modification date, etc.) and collects them into an index file. At Datashelter, for instance, this index is a CSV file containing key information such as the file paths, their sizes, modification dates, and optionally, a checksum.
- Comparison with the previous index: When a new backup is performed, this index is compared to the previously generated index. This helps identify only the changes made (new files, modified files).
- Backup of changes: Once the differences are identified, only the new or modified files or data blocks are sent to storage, significantly reducing the volume of data transferred and stored.
This process is similar to the incremental method but far more optimized, as it works directly at the file or even data block level. This allows for better resource management, especially in environments with large volumes of data or frequent backups.

Advantages over traditional methods
For instance, with a full backup, if you have 1 TB of data, each backup will require an equivalent amount of space. In contrast, an index-based backup may only back up a few gigabytes per iteration, as it only transfers the modified blocks. This not only reduces the required storage space but also the time needed for each backup.
Thus, it’s a solution that combines the advantages of the three traditional methods without inheriting their drawbacks.
Advantages
- Low storage overhead: Backing up 1 TB ten times requires only slightly more than 1 TB of final storage.
- Faster backups: Only new or modified files are sent.
- Simplified restoration: You only need to scan an index and retrieve the data it references.
- Handles file deletions: Unlike incremental backup, it allows you to restore a file system exactly as it was, without restoring files deleted before the backup.
Disadvantages
- Retaining your indexes is essential for restoring your data.
- Deleting data linked to an index requires scanning all other indexes to ensure that it’s not referenced elsewhere.
Conclusion
In conclusion, index-based backup is a direct response to modern data management needs. By indexing metadata and using a block-based approach, it optimizes resource management, reduces backup and restoration times, and integrates perfectly with cloud and object storage environments.
Modern backup software like restic (open-source), Synology HyperBackup (proprietary), and snaper (Datashelter) show that this approach is gradually becoming a standard, providing both efficiency and flexibility in data backup.


